命令行用例转换自动化测试调研
相关术语
问题
目前基于UOS专用设备系统的测试中,包含命令行模式测试和图像化页面测试,在命令行模式对应的用例中,有部分用例执行起来较为简单(操作单一、交互性弱),但是在执行起来却相当繁琐。
而且在实际测试过程中需要覆盖多个架构进行测试,重复工作较大,一条用例最多会被执行6遍,详情数据如下:
以上表格统计的用例数量并不能代表执行命令的数量,因为每一条用例可能包含多条执行命令,所以执行命令条数是远远大于用例条数的;除了以上目前问题(执行繁琐及重复工作)外,还存在以下影响效率的问题:
-
专用设备系统没有图形页面,相对于桌面版裁剪了大部分功能,用例的查看与执行是在不同设备上操作,所以无法粘贴命令,只能手动输入。
-
若用例负责人请假/离职,更换测试人员进行测试,因为对用例不熟悉,需要依次查看用例文档预期内容。
现状
以上指出的问题,解决方案为把这54.73%的用例(后续称这54.73%的用例为:A类用例,另外一部分用例称为:B类用例),从人工执行转换为自动化执行(自动执行命令、自动验证输出结果、自动生成测试报告),这样除了在全量测试时减少工作量,提升测试效率;还能在回归测试、边缘测试时多覆盖一定的测试范围。
在Linux系统上实现自动化,首先想到的是通过Shell实现,把所有用例写到一个脚本中自动执行并判断结果即可,例如:
执行以上Shell脚本即可完成对该条命令的测试,根据用例内容设计测试命令,并把命令结果赋值给变量,最后通过判断变量的情况得出结论。该方法能实现,但是当命令达到几百条并且后期还会继续增加时,那不管是代码编写还是后期维护都会越来越困难,会产生大量的代码冗余、内容无清晰等问题,所以该方案结论是测试内容少的时候可满足,但无法长远。
这样看来我们需要的是一个自动化测试框架,满足自动处理/执行测试用例、自动验证输出结果、自动生成测试报告。就目前常见的自动化测试框架来说均可满足需求,确定了以下2个方案:
-
unitest:Python标准库中的单元测试框架,支持批量导入/执行用例、提供断言、初始化环境、环境清理、通过第三方库生成测试报告等。
-
自行设计框架:根据目前需求,基于Shell自行编写一套适合项目的自动化测试框架
Shell框架和Python框架对比,Shell可直接执行系统命令,Python只能通过os、subprocess库来调用linux系统命令,在脚本的编写和调式都不如Shell简洁、方便。使用简单场景【查询音乐应用进程状态】的Shell、Python代码作为对比:
- Python
- Shell
通过以上对比可发现,在Linux系统上,实现一个相同的功能,Shell编写的代码要更为直接、简洁,命令越多越复杂这个优势越明显,对于几百条用例编写代码来说更偏向于使用Shell。
除此之外Python通过第三方库生成的测试报告格式为HTML,但是针对当前项目中的裁剪系统来说,不带GUI页面所以并不支持查看HTML的文件;Shell框架生成的测试报告不带图形化内容,可直接在被测系统上直观的看到测试结果并进行验证,所以对查看测试结果来说Shell框架更适合当前项目。
该类测试需要的测试框架不需要很复杂,轻量级的即可,通过自行设计能更自由,更贴合项目,所以最终选定通过Shell自行设计自动化测试框架方案。
技术方案
通过Shell实现设计自动化测试框架,命名为SAT,通过SAT主要实现现状部分所描述的需求:自动处理/执行测试用例、自动验证输出结果、自动生成测试报告。
SAT自动化测试框架运行流程图如下:
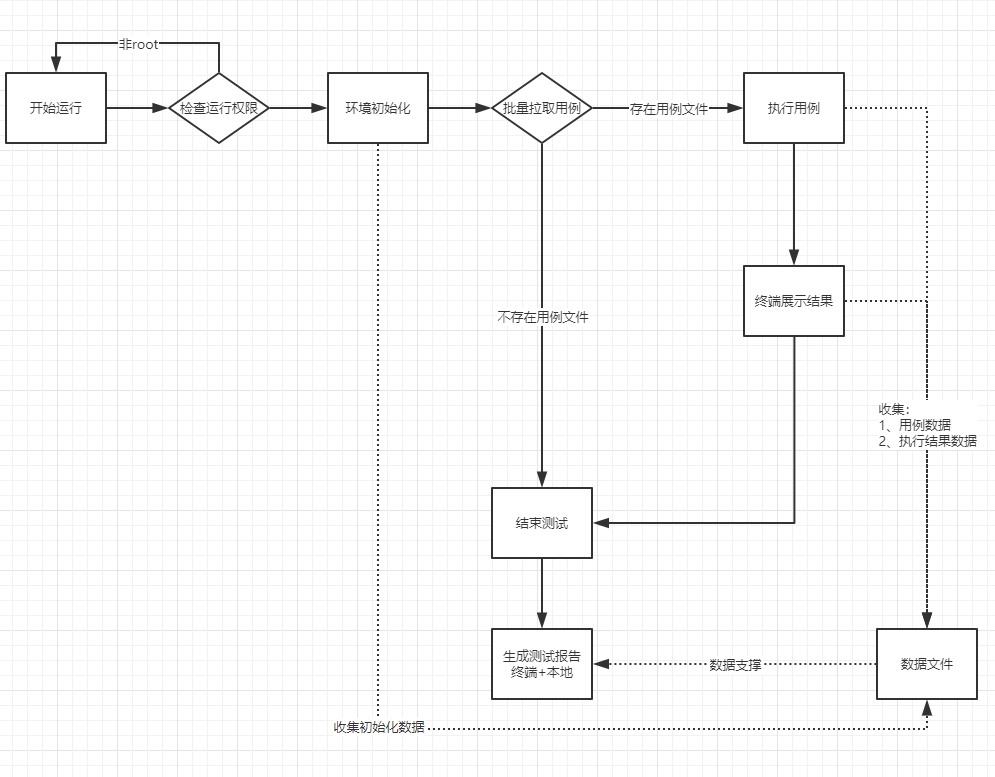
整体设计
SAT总体可以划分为下面几个模块:
-
用例模块(case):存放转换为自动化测试用例的代码,最小单位为函数,该框架支持多个用例模块文件。
-
方法封装模块(method):存放一些公用方法函数,比如:断言、测试报告等。
-
启动测试模块(run_repor):存放启动测试的主代码,对用例模块文件进行批量处理并生成测试报告。
-
SAT目录结构如下:
用例模块(case)
实际项目中每个人负责的模块与用例不同,所以自动化测试用例需要自己编写负责部分,不像其他模块中的代码都是公用的,那么在编写格式上需要做统一的约定。格式统一之后,每人完成自己部分的用例文件,在启动测试时只要汇总全部用例模块文件,即可完成所有人的测试用例执行:
- 用例模块文件命名统一,测试人员A、B的用例模块文件:case_a.sh、case_b.sh。
- 测试用例最小单位统一:每一条测试用例为一条函数,通过函数来管理用例。
- 用例函数命名统一,测试人员A的第1、2条用例:test_a1()、test_a2()。
- 用例函数元素统一,需要包含变量:title、case_id、断言函数。
方法封装模块(method)
该模块主要用于存放公共方法函数,其他模块直接调用即可,使代码更为清晰简洁,并减少冗余。封装的函数主要实现以下功能:
- 用例断言:判断用例执行结果与预期是否一致,给出对应输出结果。
- 用例处理:批量处理不同的用例模块文件:执行不同的用例模块文件,输出用例执行结果。
- 用例统计:统计用例执行的数据:统计执行用例数量、通过用例数量、失败用例数量、失败用例编号。
- 测试报告:结合以上全部内容输出本地文档,方便测试结果归档保存。
启动测试模块(run_repor)
该模块为执行测试的主模块,主要是对测试开始前环境做初始化并运行测试,主要包含:
-
模块初始化:导入方法模块;根据对用例模块文件的分析,导入对应的模块文件。
-
变量初始化:针对一些数据统计相关的函数做初始化赋值:用例数量、用例通过/失败数量、定义数组变量等。
-
运行测试:调用测试执行函数、测试报告生成函数、提示用户测试报告生成路径。
关键技术
这里主要选取部分关键功能的设计与实现做说明:
-
测试用例
-
初始化
-
断言
-
执行测试
-
测试报告
测试用例文件功能
测试用例文件为管理用户用例的最小单位,每次测试至少包含1份测试用例文件,即可开始正常测试。可放入的测试文件数量无上限,可无限累加。
查看测试人员A的用例模块文件 "case_a.sh" 部分内容:
通过以上代码可看出,用例函数中包含:
-
执行用例信息:用例标题、用例编号
-
命令执行结果
-
命令执行预期结果
-
断言判断结果
完成该条用例的测试后,针对用例末尾的
assert类断言函数内部,做了特殊处理,可以收集以上所有数据为最终的测试报告提供数据支撑。
初始化功能
该功能是为后续测试提供良好的运行环境,以下为初始化函数代码:
通过代码分析,初始化/清理环境函数设计内容及流程:
-
测试开始前执行初始化函数,为后续测试提供环境支持
- 公共区域:针对框架本身的初始化
- 判断用户执行测试时是否是root用户,因为部分系统命令需要root权限,若非root用户则提示用户并退出
- 导入公共函数文件,提供公共函数的调用
- 初始化变量(变量赋值、定义变量类型),为最终的测试报告提供数据支撑
- 扫描测试用例文件,收集数据(包含多少份文件、每份文件包含多少条用例),为最终的测试报告提供数据支撑
- 独立区域:针对各测试人员,存放各自独立维护的初始化函数(比如测试人员a的,初始化函数:setup_a)
- 公共区域:针对框架本身的初始化
-
测试结束后执行环境清理函数
-
公共区域:针对框架本身的环境清理
- 清理/释放测试过程中生成的垃圾文件或资源占用(该内容暂时缺失,因示例中用例暂未涉及)
- 根据用例执行情况返回状态:用例均为pass返回0,用例存在fail返回1,后期可配合CI/CD使用
-
独立区域:针对各测试人员,存放各自独立维护的清理函数(比如测试人员a的,环境清理函数:teardown_a)
-
断言功能
该功能实现的是在每条用例执行之后,对用例执行结果与预期结果对比,判断用例执行结果(通过/失败),并且对结果进行输出与数据收集。
断言对比的方法多种多样,这里拿部分举例,详情见下方代码:
通过代码分析,初始化设计内容及流程:
- 通过判断用例的执行结果与预期结果是否一致
- 判断输出结果,通过输出pass,失败输出fail(如底部截图)
- 针对fail的用例id至数组变量,便于在拿到测试报告后验证复盘
- 代码末尾的
case_pf函数针对以上所有数据做了数据处理与收集(递增通过/失败/执行用例数量),为最终的测试报告提供数据支撑

测试执行功能
该功能主要是实现不同用例模块中,用例的批量执行:
具体代码如下:
通过代码可看出,这里除了实现用例的批量执行外,还包含了一些其他设计:
-
获取测试开始时间
-
初始化测试报告文件(创建、命名、赋值路径)
-
针对测试结果输出做了双向处理:输出至终端、输出至本地测试报告文件
-
针对测试结果的输出样式做了排版,使之更为美观
-
展示即将测试的用例数据(如底部截图)
-
依次执行每个测试文件中的用例
-
执行用例中
test_result函数是处理用例执行结果,使之格式化输出
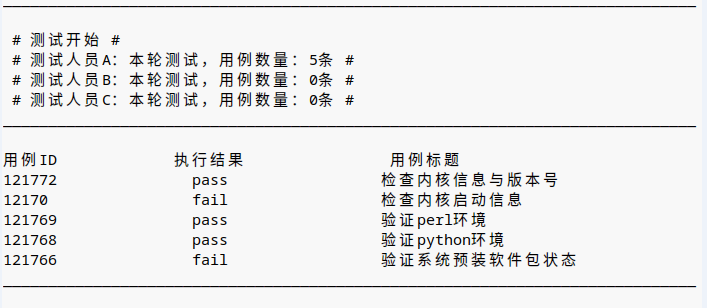
测试报告功能
该功能主要实现测试结果的展示,通过分析测试结果获取失败用例信息,验证并提交Bug。同时还有一个重要作用是针对这次测试结果做归档,便于在不同时间查看本次测试结果,具体实现代码如下:
通过分析代码,该功能工作流程为:
- 通过辅助函数
case_pf、test_result分散在测试过程中关键位置,收集测试过程中产生的关键数据 - 获取测试结束时间
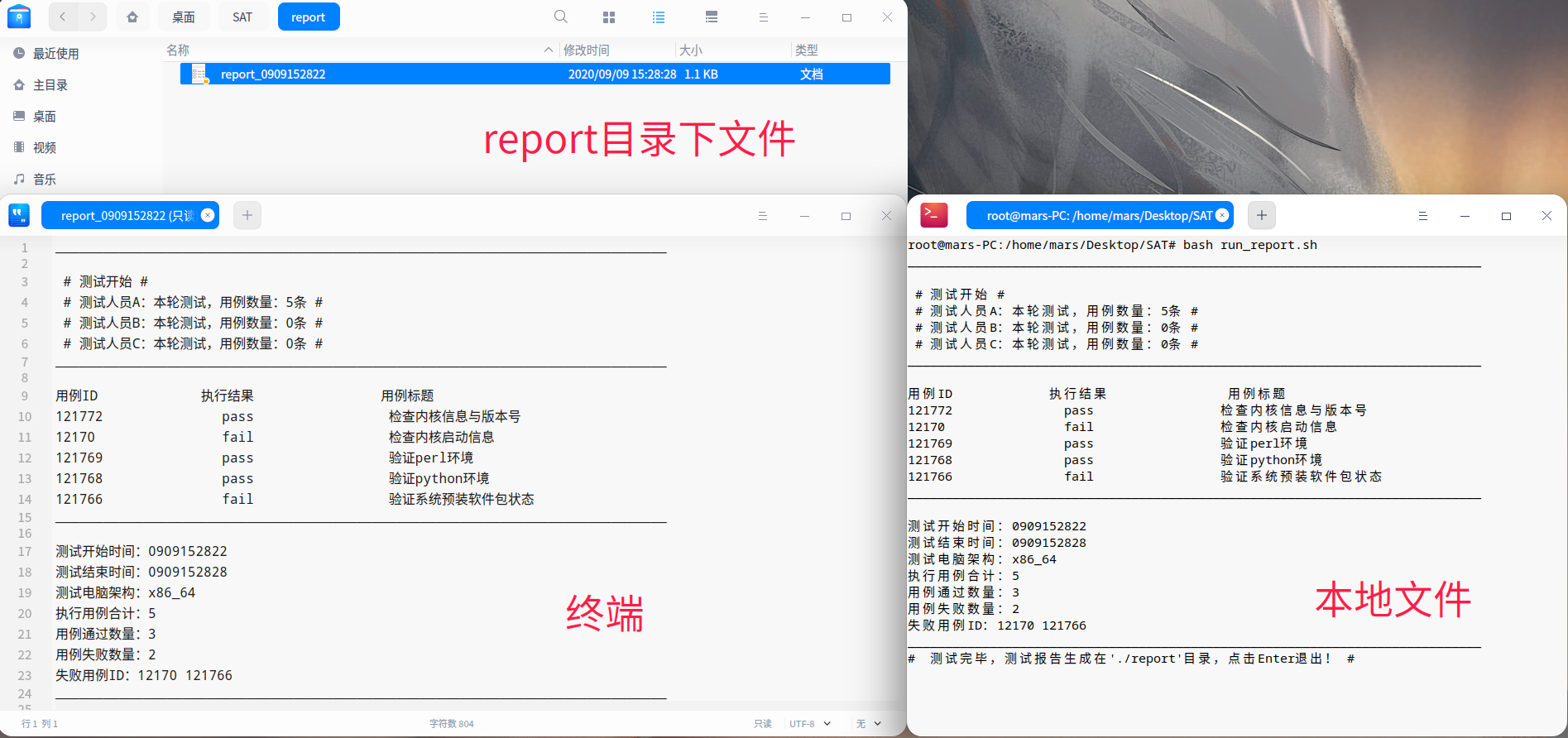
- 通过测试过程中收集到的数据,汇总整理成结果呈现给用户(如底部截图)
- 测试结果同样双向输出至:终端、本地测试报告文件
实验验证
现状与方案初步对比
| 用例标题 | 步骤 | 预期 |
| [t]基础命令:验证touch基础命令功能正确 | 1、 在命令行输入:touch /opt/test2.txt | 1、创建test2.txt文件成功 |
| 2、在命令行输入:stat /opt/test2.txt | 2、查看test2.txt文件详情成功 | |
| 3、在命令行输入:cat /opt/test2.txt | 3、打开test2.txt文件正文为空 | |
| 4、在命令行输入:ls -l | 4、文件时间信息正常 | |
| 5、在命令行输入:touch /opt/test2.txt | 5、覆盖步骤1创建的文件 | |
| 6、在命令行输入:ls -l | 6、时间信息成功更新 |
以上为一条实际存在的A类测试用例,我们模拟一下手工执行和自动化执行对比:
-
手工执行模拟:
- 执行步骤1:命令行中输入命令
touch /opt/test2.txt - 验证步骤1:查看步骤1输出结果,验证结果与用例中预期是否一致
- 执行步骤2:命令行中输入命令
stat /opt/test2.txt - 验证步骤2:查看步骤2输出结果,验证结果与用例中预期是否一致
- 执行步骤3:命令行中输入命令
cat /opt/test2.txt - 验证步骤3:查看步骤3输出结果,验证结果与用例中预期是否一致
- 执行步骤4:命令行中输入命令
ls -l - 验证步骤4:查看步骤3输出结果,验证结果与用例中预期是否一致
- 执行步骤5:命令行中输入命令
touch /opt/test2.txt - 验证步骤5:查看步骤3输出结果,验证结果与用例中预期是否一致
- 执行步骤6:命令行中输入命令
ls -l - 验证步骤6:查看步骤3输出结果,验证结果与用例中预期是否一致
- 执行步骤1:命令行中输入命令
通过手工执行以上用例,大致估算完成每个步骤(输入命令、验证结果、用户思考)的耗时为10秒,那么执行完这条用例需要的耗时为==60==秒。
- 自动化执行模拟
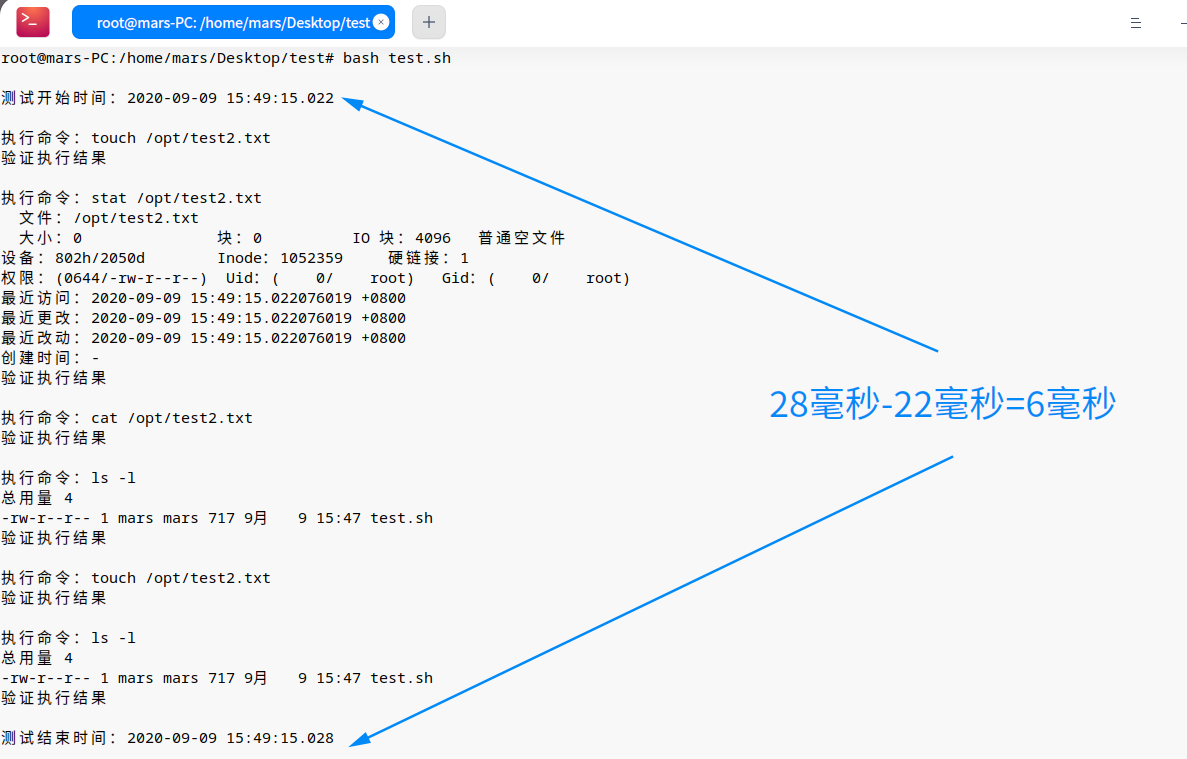
通过上面的例子可看出,测试人员手工执行耗时==60秒==的用例,若通过自动化执行该条用例,耗时只需要==6豪秒==(后续按0.01秒算),A类用例有283条,假设每条用例的平均耗时为60秒,那么执行耗时对比如下:
通过差异数据对比,可看出A类用例从手工转化为自动化后可大量提升执行效率,相比手动执行耗时的==16980秒==,自动化执行耗时的==2.83秒==可忽略不计。
完整的全量测试流程中耗时分布大致为:
-
执行全测试用例:占比60%(按平时测试经验,A类用例与B类用例,执行耗时占比大致为1:4)
-
分析失败用例,提交Bug单:占比15%
-
验证异常情况:5%
-
发散交互性测试:10%
-
回归Bug,针对Bug进行边缘测试,处理Bug单:10%
计算效率提升率:
结合以上数据,可得出结论实现自动化技术后,每次全量测试,==A类用例部分==执行耗时可比之前手工测试提升效率==15%==,且能够较好解决当前面临的问题。
模拟一次完整测试
为了演示SAT的工作流程,这里拿一个实际场景举例,本次测试需要自动化执行:测试人员A的用例5条、测试人员B的用例1条,无需执行测试人员C的用例:
执行流程如下:
-
收集测试人员A、测试人员B最新的测试用例文件,放入目录
SAT/case/下 -
SAT目录下启动终端,运行命令
su进入Root- 因部分命令需要root权限,使用sudo+命令需要提示用户输入密码,不友好。
- 若用户使用普通用户权限运行,则给出对应提示:
请已root用户运行该脚本,点击Enter退出,并关闭。
-
初始化环境:导入依赖文件、扫描测试用例文件并分析数据、变量初始化赋值/定义
-
终端输出即将测试的内容
-
开始测试并输出每条测试用例的执行结果
-
所有用例执行完毕,整理测试过程中获取的数据
-
生成测试报告:测试起止时间、电脑架构、执行用例数量、通过/失败用例数量、失败用例编号、本地测试报告存放路径
-
根据测试报告中失败用例编号,验证复盘并提交BUG单
-
测试完成
输出结果如下:
依赖库相关信息
实验代码存放地址
小结
SAT实现的自动化测试,通过实验验证部分得出的结论,可看出每次全量测试,A类用例部分执行部分效率可提高15%。而且每次回归测试时,除了Bug回归和边缘测试,也可以自动化执行一次A类用例,就用例覆盖面来说提升了54.73%。同时解决了当前所面临的问题:
-
手工测试时针对A类用例时,繁琐的输入、验证
-
覆盖多个架构测试时,大量的重复性工作
除此之外SAT是自行设计的,有较高的扩展性,可根据后续项目的变动对框架内容作出对应调整(优化、新增功能),而且框架是通用的,不同项目间也可以同时使用,只要按照约定编写测试用例代码,把用例文件放在在SAT/case/目录下,即可运行测试。
再往后说,随着SAT内容越来越丰富,创新性越来越多时,可把该方案转换为对应的创新性发明专利。