Playwright—8小时入门版
一、简介
Playwright 是一个 Web UI 自动化测试的框架,其各方面功能和使用体验全面碾压 Selenium。
一入 Playwright 深似海,从此 Selenium 是路人。
曾经,在 Web UI 自动化测试领域,Selenium 如日中天,几乎只要提到 UI 自动化就会想到 Selenium,Selenium 就是 Web UI自动化的代名词;
后来,Playwright 出现了,慢慢的大家对 Selenium 开始冷落了;为啥呢?
简单讲,因为在 Selenium 时代,其实大家遇到很多问题,但一直得不到解决;Selenium 2.0 版本是一个巨大的飞跃,因为引入了 WebDriver,后面 3.0、到现在 4.0 功能上没有什么亮点,而且以前的问题还在,大家对这个玩意儿就提不起兴趣去研究了。
Selenium 之后不是没有其他 UI 框架,确实也出现过几个小有名气的框架,比如:cypress、puppeteer、testcafe,这些个玩意儿缺点就是不支持 Python,太拉胯,而且像 puppeteer 只支持谷歌浏览器,因为它就是谷歌家的它不需要支持其他浏览器,就这,广大的 Firefox 和尊贵的 Safari 用户能忍你吗,给老子滚。于是,Playwright 集各家之所长,补各家之缩短,“天空一声巨响,老子闪亮登场”。
坊间传言,Playwright 有几个核心开发者就是从 puppeteer 过来的,不得不说,老外是真会整活。
第一次尝试使用 Playwright,我仅仅只写了一个小脚本,但有两个点印象深刻:
1、环境安装好简单;
要知道 Selenium 的环境安装是很烦人的,要单独装 WebDriver 的驱动,而且驱动版本要和浏览器版本一致,不然会报一些莫名其妙的错,多少人在 Selenium 的环境上卡住而无法入门;
2、执行速度好快;
用过 Selenium 应该知道,跑起来挺慢的,Playwright 的执行速度真的“起飞”。
在后面对 Playwright 使用和了解越来越多之后发现,它确实全面碾压 Selenium。微软出品,必属精品。
二、安装
系统环境:deepin-20.8
pip3 install playwright
# 安装浏览器
playwright install完事儿了,这样环境就装好了,是不是很简单,不用去关心用什么浏览器,用什么 WebDriver 驱动,你的电脑上甚至不用装浏览器,playwright install 已经把测试用的浏览器都装好。
三、脚本生成器
Selenium IDE 是用来录制脚本的,好多刚开始入门的同学应该都用过,就是在浏览器里面装个插件,然后监控浏览器的事件,生成脚本;我个人倒是极少用,因为会写代码用那玩意儿干啥。(成功装到)
Playwright 当然也有录制的功能,在终端执行:
playwright codegen会启动一个“浏览器”窗口和一个“脚本生成器”窗口
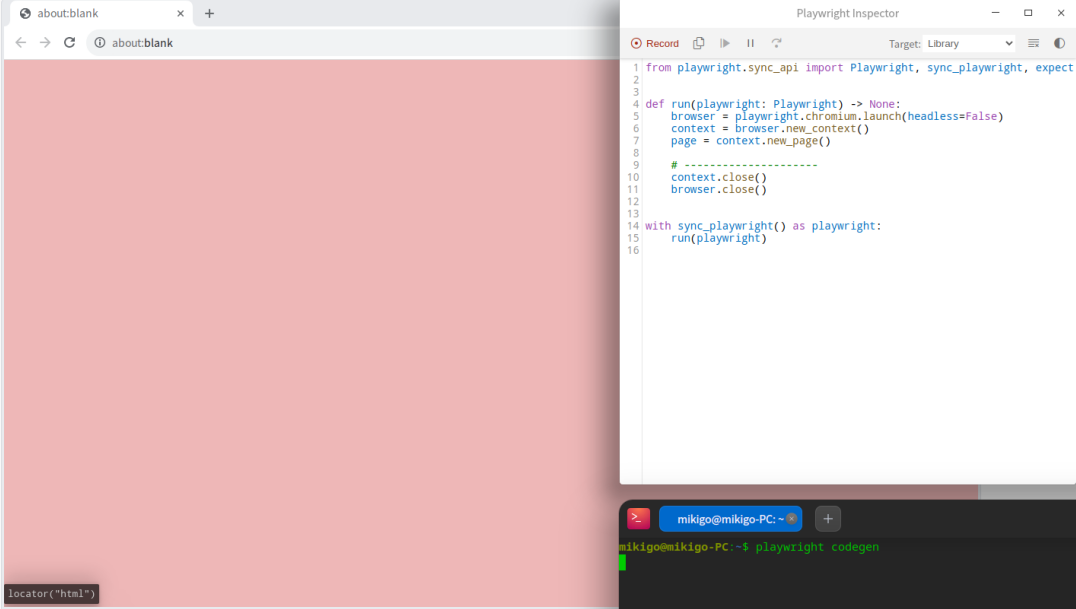
脚本生成器初始状态会有模板代码,你通过浏览器操作的时候,每一步的操作,都会对应在脚本生成器自动生成一行代码,比如,我输入百度的网址:
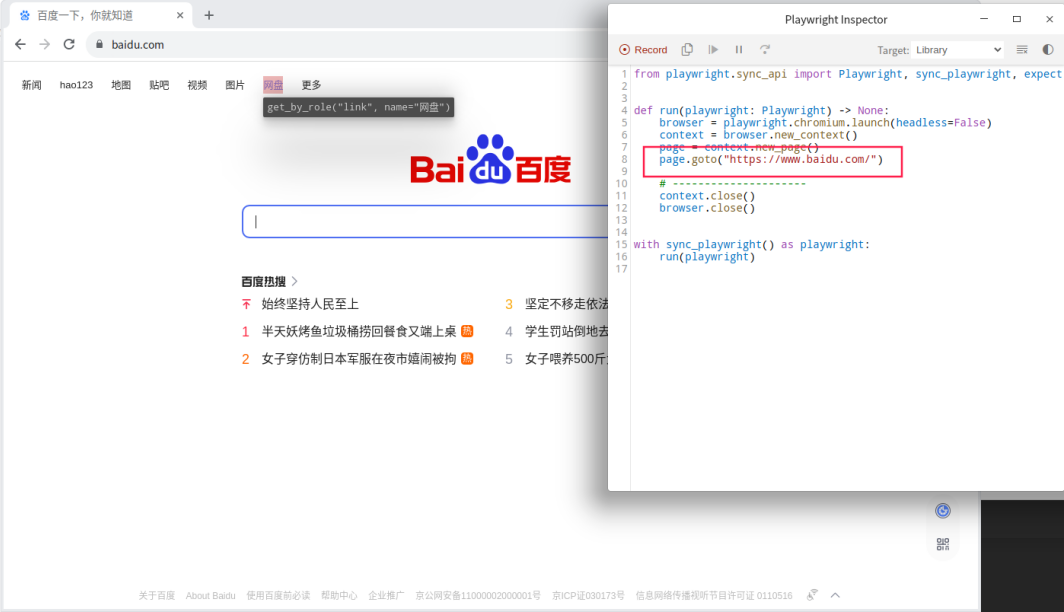
在百度首页,点击输入框,输入一个内容,点击“百度一下”,一顿操作下来,代码自动生成如下:
from playwright.sync_api import Playwright, sync_playwright, expect
def run(playwright: Playwright) -> None:
browser = playwright.chromium.launch(headless=False)
context = browser.new_context()
page = context.new_page()
page.goto("https://www.baidu.com/")
page.locator("#kw").click()
page.locator("#kw").fill("youqu")
page.get_by_role("button", name="百度一下").click()
# ---------------------
context.close()
browser.close()
with sync_playwright() as playwright:
run(playwright)这样就自动生成了一段完整的代码,简直不要太轻松。
有同学说,能不能直接生成测试用例的代码,当然是可以的,在脚本生成器右上角 Target 选择 pytest,一顿操作下来,生成代码如下:
from playwright.sync_api import Page, expect
def test_example(page: Page) -> None:
page.goto("https://www.baidu.com/")
page.locator("#kw").click()
page.locator("#kw").fill("youqu")
page.get_by_role("button", name="百度一下").click()这个脚本是可以直接用 pytest 来执行的,你需要安装 pytest-playwright 插件:
pip3 install pytest-playwrightpytest-playwright 插件是由 Playwright 官方维护的。
相信有上面 pytest 这个例子,对于测试同学来讲,写一些简单的用例是没什么问题了。
四、元素定位方法
对于所有的 UI 自动化来讲,无非就是元素定位和元素操作,Playwright 最常用的元素的定位方法就是 XPath 和 CSS,其次就是它特有的定位方法;
1、XPath
XPath 是一种通用、标准的元素定位方案,它的语法也是标准的,在很多框架里面都有使用到,基本能满足 90% 的元素定位需求;
经常有同学说 XPath 定位不稳定,页面上一点点变化就找不到元素了,说这话的一般是喜欢使用浏览器自带的复制 XPath 的功能,因为复制出来的 XPath 路径是绝对路径,当然不稳定,我们通过观察,自己写相对路径的XPath 表达式;
简单介绍下 XPath 语法:
(1)节点选取
| 表达式 | 描述 |
|---|---|
| nodename | 选取此节点的所有子节点 |
| / | 从根节点选取 |
| // | 从匹配选择的当前节点选择文档中的节点,而不考虑它们的位置 |
| . | 选取当前节点 |
| .. | 选取当前节点的父节点 |
| @ | 选取属性 |
(2)属性选取
| 路径表达式 | 结果 |
|---|---|
| /bookstore/book[1] | 选取属于 bookstore 子元素的第一个 book 元素。 |
| /bookstore/book[last()] | 选取属于 bookstore 子元素的最后一个 book 元素。 |
| /bookstore/book[last()-1] | 选取属于 bookstore 子元素的倒数第二个 book 元素。 |
| /bookstore/book[position()❤️] | 选取最前面的两个属于 bookstore 元素的子元素的 book 元素。 |
| //title[@lang] | 选取所有拥有名为 lang 的属性的 title 元素。 |
| //title[@lang='eng'] | 选取所有 title 元素,且这些元素拥有值为 eng 的 lang 属性。 |
| /bookstore/book[price>35.00] | 选取 bookstore 元素的所有 book 元素,且其中的 price 元素的值须大于 35.00。 |
| /bookstore/book[price>35.00]/title | 选取 bookstore 元素中的 book 元素的所有 title 元素,且其中的 price 元素的值须大于 35.00。 |
在浏览器中调试 XPath:
按 F12 打开调试页面—>选择 console,XPath 定位的语法是 :$x()
举例:
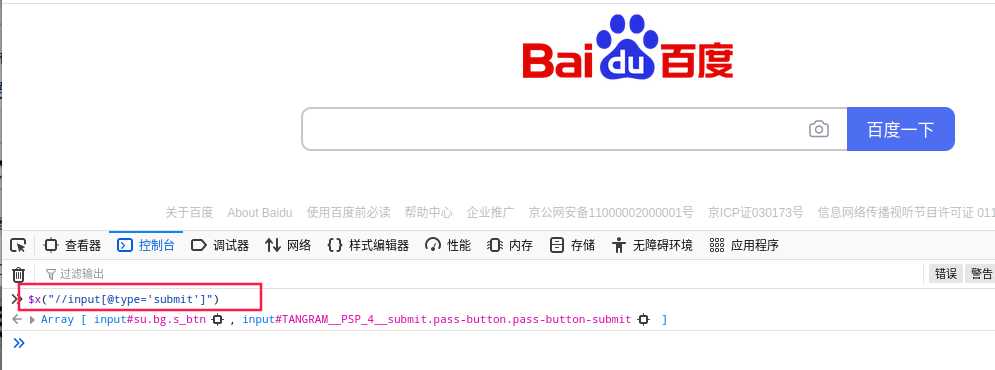
$x("//input[@type='submit']")说明通过这个 XPath 表达式可以定位到【百度一下】按钮;
在 Playwright 里面是通过 page 对象提供的 locator 方法实现 CSS 或 XPath 定位的:
page.locater("//input[@type='submit']").click()Playwright 会自动检测输入的是 CSS 或 XPath。
2、CSS
了解前端的应该都知道 CSS,这里不多介绍;
在浏览器中调试 CSS 定位:

$("#su")说明通过此 CSS 表达式可以定位到【百度一下】按钮;
在 Playwright 里面:
page.locater("#su").click()3、特有的
Playwright 内置几个定位器:
get_by_role 通过角色定位
还是上面的例子【百度一下】:
html 是这样的:
html<input type="submit" id="su" value="百度一下" class="bg s_btn">定位可以这样写:
pythonpage.get_by_role("button", name="百度一下")get_by_text 通过文本定位
还是在百度首页找个文本 html :
html<span class="hot-refresh-text">换一换</span>定位可以这样写:
pythonpage.get_by_text("换一换")get_by_label 通过标签定位
html 是这样的:
html<label>Password <input type="password" /></label>定位可以这样写:
pythonpage.get_by_label("Password")
还有其他的内置定位方法:
get_by_placeholder 占位符定位
get_by_alt_text 替换文本定位
get_by_title 标题定位
get_by_test_id 测试ID定位五、其他
1、截图
捕获屏幕截图并将其保存到文件中:
page.screenshot(path="screenshot.png")完整页面截图是一个完整的可滚动页面的截图:
page.screenshot(path="screenshot.png", full_page=True)单个元素进行屏幕截图:
page.locator(".header").screenshot(path="screenshot.png")2、录屏
测试过程录屏,保存的视频文件将出现在指定的文件夹中,生成了唯一的名称,视频保存在浏览器上下文在测试结束时关闭:
context = browser.new_context(record_video_dir="videos/")
context.close()还可以指定视频大小
context = browser.new_context(
record_video_dir="videos/",
record_video_size={"width": 800, "height": 800}
)3、PO
PO(Page Object) 是一种分层设计的思想,最早是 Selenium 提出来的,但它本身和使用什么框架没有关系,我们在自动化测试实践过程中,应该始终使用 PO 的设计;
4、自动等待
Playwright 在元素定位的时候是自动等待的,不用再像使用 Selenium 一样设置各种类型的等待(隐式等待、显示等待、强制等待),这才是框架该有的样子。
5、断言
Playwright 有自己的断言语句:
locator = page.locator("input[type=number]")
expect(locator).to_have_value(re.compile(r"[0-9]"))使用 expect 语句,后面跟断言的类型,断言的类型就有点多了,大概看了下有好几十个,列几个常用的:
to_have_value
to_contain_text
to_be_empty
反向断言,前面加 not,如:not_to_contain_text